SpinSci-Ex: Empowering Automated Information Extraction from Scientific Literature
2025-08-28 · 3 min read
With the rapid development of the new materials field, the volume of scientific literature is growing exponentially. However, the critical experimental data contained within these publications—such as manufacturing parameters, material morphology, and functional properties—mostly exist in unstructured text, creating significant "information silos." The challenge of efficiently and accurately unlocking this valuable data from massive text collections has become key to accelerating innovation in materials science.
To meet this challenge, the SpinSci-Ex project was initiated. It is a deep-learning-based framework for automated information extraction, specifically designed to solve the problem of data extraction from literature in the field of electrospinning.
Project Background: Tackling the "Data Deluge" in Materials Science
Electrospinning technology has generated a vast body of research due to its wide applications in biomedicine, filtration materials, and more. These publications contain a wealth of parameters that determine material performance, making them an invaluable asset for data-driven research, building predictive models, and optimizing process flows.
Traditional manual data extraction is not only inefficient and costly but also struggles to ensure consistency and accuracy. Therefore, developing an intelligent system that can automatically "read" and "understand" scientific literature to build a structured knowledge base is of significant practical importance and application value.
Technical Solution: Building a Professional "Reading Comprehension" Model for Materials Science
The core of the SpinSci-Ex framework is the use of a domain-specific large language model's powerful natural language processing capabilities, implementing an information extraction pipeline that combines "Named Entity Recognition (NER)" and "Relation Extraction (RE)."
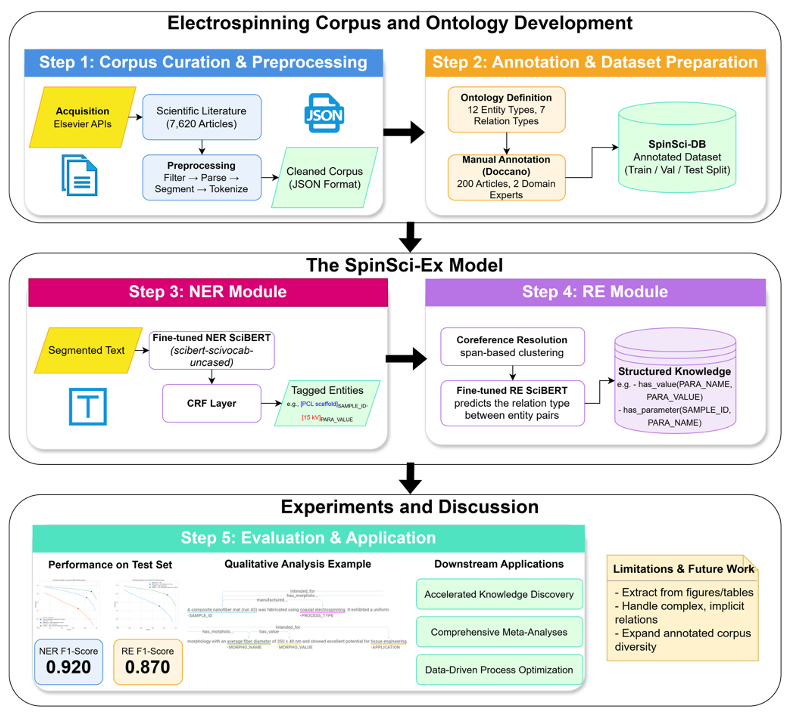
1. Data Foundation: A Customized Electrospinning Corpus and Ontology Design
A high-quality, specialized dataset is the cornerstone of a successful model. This project started from scratch to build a domain-specific knowledge base named SpinSci-DB.
- Corpus Construction: The project team collected over 7,600 full-text professional articles on electrospinning. Domain experts performed fine-grained manual annotation on 200 of these articles, creating a gold-standard dataset for model training and evaluation.
- Ontology Schema Design: To ensure the extracted information is structured and logical, the project designed a sample-centric ontology schema. All key information, such as manufacturing parameters and morphological features, is linked to a unique sample ID through predefined relations (e.g.,
has_parameter,has_morphology), laying a solid foundation for subsequent knowledge graph and database construction.
2. Core Model: A Joint NER and RE Engine Based on SciBERT
The language style and technical terminology of scientific literature differ greatly from general text. Therefore, this project chose the domain-specific large language model SciBERT as its core technology, rather than a general-purpose BERT model. SciBERT is pre-trained on a massive corpus of scientific texts, giving it a vocabulary and contextual understanding of science that far surpasses general models.
- Named Entity Recognition (NER) Module: By fine-tuning the SciBERT model, it can accurately identify 12 predefined entity types in the text (e.g.,
POLYMER,PARA_VALUE). A Conditional Random Field (CRF) layer was added on top of the model to ensure the coherence and accuracy of entity boundary recognition. - Relation Extraction (RE) Module: After identifying individual entities, the RE module is responsible for resolving the semantic relationships between them. For instance, it can link "voltage" with its value "15 kV" and then associate the "voltage" parameter with a specific "Sample A." This module is also based on a SciBERT classifier.
Results and Discussion
Evaluation on the SpinSci-DB test set shows that the SpinSci-Ex framework delivered outstanding performance:
- On the Named Entity Recognition (NER) task, the F1-score reached 0.920.
- On the Relation Extraction (RE) task, the F1-score was 0.870.
Notably, the use of the domain-specific model SciBERT led to a significant performance leap compared to the general BERT model (e.g., the NER F1-score increased from 0.843 to 0.920). This strongly proves that selecting and optimizing a domain-specific large language model is a key strategy for success when dealing with highly specialized tasks.
In conclusion, the SpinSci-Ex project successfully demonstrates how to apply deep learning, particularly domain-specific large language model technology, to solve information extraction challenges in a specific scientific field. This framework not only frees researchers from tedious data organization work but also holds the potential to provide powerful support for data-driven materials science research by building a systematic knowledge base, thereby accelerating the innovation cycle for new materials.