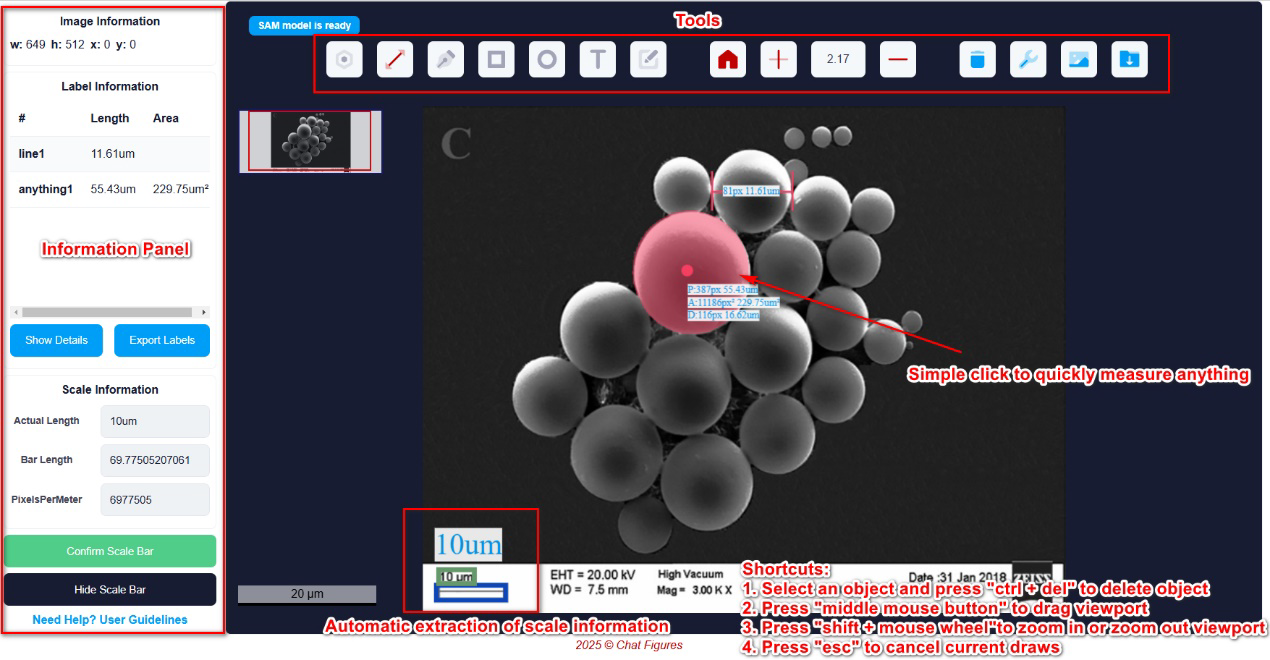
From Seeing to Measuring: How AI Measures Anything in Microscopy Images
2025-08-28 · 3 min read
In biomedical and materials science research, microscopy images are our windows into the mysteries of the microscopic world. However, merely "seeing" is not enough; precise "measuring"—such as calculating cell sizes, fiber diameters, or particle distributions—is what truly drives scientific progress. The prerequisite for all this quantitative analysis depends on a seemingly simple yet crucial element: the image scale bar.
Project Background: The Missing Link in Quantitative Analysis
In the traditional workflow of quantitative analysis, researchers need to manually calibrate the scale bar in software like ImageJ. This process is not only tedious and time-consuming but also highly susceptible to subjective errors. A more challenging issue is that microscopy images from different journals and equipment feature a vast variety of scale bar styles, from simple lines to complex rulers, posing a significant challenge for automated processing.
Recently, large vision models like SAM (Segment Anything Model) have shown powerful "segment anything" capabilities. However, they answer the "what it is" question but not the "how big it is" question. Without automatically obtaining the physical scale of an image, these advanced segmentation models are rendered useless for quantitative analysis. This project aims to bridge this "last mile" by developing an AI system that can automatically and accurately extract various types of scale information and integrate it with segmentation models to truly achieve "measure anything."
Technical Solution: An End-to-End System for Recognition and Interactive Measurement
The core of this project is an end-to-end intelligent system composed of two parts: a YOLO-OCR model for automatically extracting scale information, and an interactive measurement front-end powered by MicroSAM that integrates this information.
1. Data-Driven Approach: Building the World's First Large-Scale Scale Bar Dataset
Due to the lack of publicly available datasets, the project first constructed a large-scale scale bar dataset (SciScale-DB) containing 14,000 real scientific images and 5,726 synthetic images. The dataset covers eight common scale bar styles, including rectangular, I-shaped, and arrow-shaped. By pre-training on synthetic data and then fine-tuning with active learning on real data, the project significantly reduced annotation costs and improved the model's generalization ability.
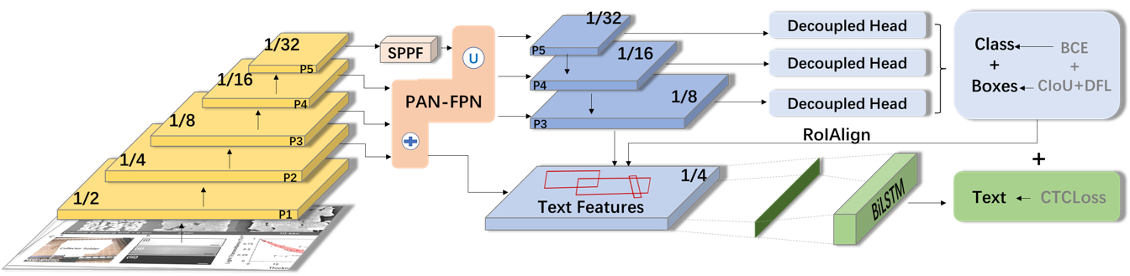
2. Core Model YOLO-OCR: Unifying Object Detection and Text Recognition
Unlike the two-stage approach of "first detect the box, then recognize the text," this project uses an improved end-to-end YOLO-OCR model. Based on the advanced YOLOv11 architecture, this model performs three tasks simultaneously within a unified network:
- Scale Bar Detection
- Scale Label Detection
- Scale Label Text Recognition
This end-to-end design allows the model to leverage the contextual information that scale bars and their labels typically appear together, thereby improving overall recognition accuracy and efficiency.
3. System Integration: Empowering "Measure Anything" with SAM
The extracted scale information (e.g., 100 pixels correspond to 10 micrometers) is seamlessly integrated into an interactive measurement system. The front-end of this system utilizes MicroSAM—a SAM model fine-tuned on a massive dataset of microscopy images. Users only need to simply click or box the region of interest in an image, and the system can:
- Automatically segment the target object.
- Instantly calculate the object's real physical dimensions (such as diameter, area, etc.).
Results and Validation
1. High-Precision Recognition Performance
On a test set of 1,400 images, the YOLO-OCR model demonstrated outstanding performance:
- The detection precision for scale bars and labels reached 98.0%.
- The text recognition accuracy for scale labels reached 96.6%.
This performance is significantly better than traditional two-stage methods, proving the superiority of the unified end-to-end model.
2. Comparison with General-Purpose Large Vision Models
To validate the advantage of a specialized model on a specific task, the project compared the quantitative analysis capabilities of this system with several top-tier general-purpose multimodal large models (like ChatGPT-4o, Gemini 1.5 Pro). The task was to estimate the physical size of a specific object in an image.
3. Interactive Online Application
The final output of the project is a publicly available online web application (AI-Fiber). It provides an intuitive interface where users can upload local images or use a browser extension to directly analyze microscopy images on any webpage. This truly achieves "see and measure instantly," significantly lowering the technical barrier for researchers to perform quantitative analysis.