SpinSci-Ex:用领域大模型自动“阅读”海量科研文献
2025-08-28 · 5 min read
随着新材料领域的飞速发展,科研文献数量呈爆炸式增长。然而,海量文献中蕴含的关键实验数据——如制造参数、材料形貌和功能属性——大多以非结构化文本形式存在,形成了巨大的“信息孤岛”。如何高效、精准地从海量文本中解锁这些宝贵数据,已成为加速材料科学创新的关键挑战。
为此,SpinSci-Ex项目应运而生。这是一个基于深度学习的自动化信息提取框架,专为解决静电纺丝(Electrospinning)领域的文献数据提取难题而设计。
项目背景:应对材料科学领域的“数据洪流”
静电纺丝技术因其在生物医学、过滤材料等领域的广泛应用,催生了大量的研究成果。这些成果中包含了决定材料性能的各类参数,是进行数据驱动研究、构建预测模型和优化工艺流程的宝贵财富。
传统的人工数据提取方式不仅效率低下、成本高昂,且难以保证一致性和准确性。因此,开发一种能够自动“阅读”并“理解”科研文献、构建结构化知识库的智能系统,具有重要的现实意义和应用价值。
技术方案:构建一个专业的材料科学“阅读理解”模型
SpinSci-Ex框架的核心是利用领域大模型强大的自然语言处理能力,通过“命名实体识别 (NER)”与“关系抽取 (RE)”相结合的技术流水线,实现端到端的信息提取。
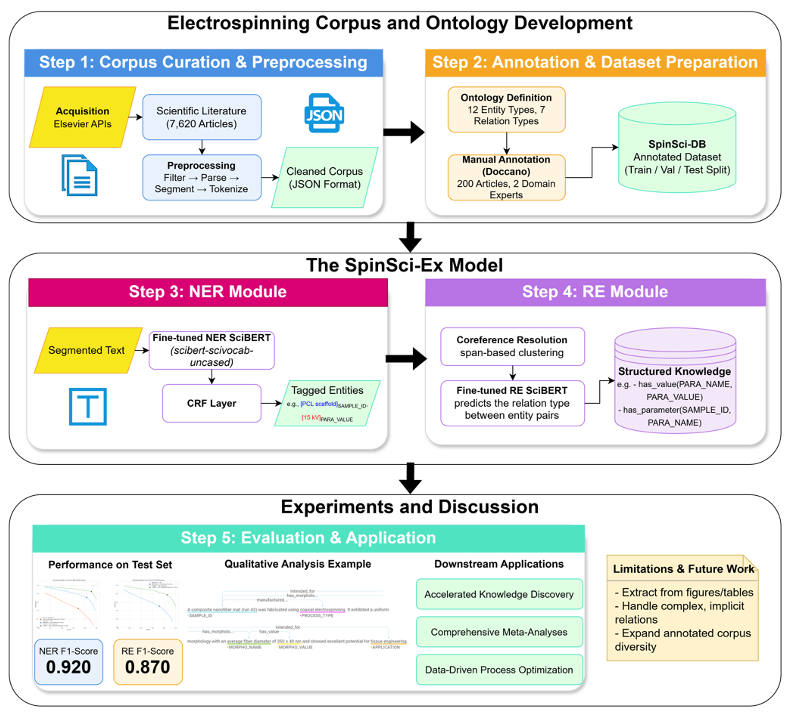
1. 数据基础:定制化的静电纺丝语料库与本体设计
高质量、专业化的数据集是模型成功的基石。此项目从零开始构建了一个名为SpinSci-DB的领域专属知识库。
- 语料库构建:项目团队收集了超过7,600篇静电纺丝领域的专业文献,并由领域专家对其中200篇进行了精细化标注,形成了用于模型训练和评估的黄金标准数据集。
- 本体Schema设计:为确保提取信息的结构化和逻辑性,项目设计了一套以“样品 (Sample)”为核心的本体论schema。所有关键信息,如制造参数、形貌特征等,都通过预定义的关系(如
has_parameter,has_morphology)与唯一的样品ID相连接,为后续构建知识图谱和数据库奠定了坚实基础。
2. 核心模型:基于SciBERT的NER与RE联合引擎
科研文献的语言风格和专业术语与通用文本存在巨大差异。因此,该项目选择领域大模型SciBERT作为核心技术底座,而非通用的BERT模型。SciBERT在海量科学文本上进行预训练,其词汇体系和对科学语境的理解能力远超通用模型。
- 命名实体识别 (NER) 模块:通过微调SciBERT模型,使其能够精准识别文本中12种预定义的实体类型(如
POLYMER,PARA_VALUE等)。模型顶部还增加了一个条件随机场 (CRF) 层,以确保实体边界识别的连贯性和准确性。 - 关系抽取 (RE) 模块:在识别出实体后,RE模块负责解析它们之间的语义关系。例如,它能将“电压”与其值“15 kV”关联,再将“电压”这一参数与具体的“样品A”关联起来。该模块同样基于一个SciBERT分类器实现。
结果与讨论
在SpinSci-DB测试集上的评估结果表明,SpinSci-Ex框架性能卓越:
- 在命名实体识别 (NER) 任务上,F1分数高达 0.920。
- 在关系抽取 (RE) 任务上,F1分数达到了 0.870。
值得注意的是,相较于通用BERT模型,领域模型SciBERT的应用带来了性能上的巨大飞跃(NER任务F1分数从0.843提升至0.920)。这充分证明了在处理高度专业化的任务时,选用并优化领域大模型是取得成功的关键策略。

总结而言,SpinSci-Ex项目成功展示了如何应用深度学习,特别是领域大模型技术,来解决特定科研领域的信息提取难题。该框架不仅能够将研究人员从繁琐的数据整理工作中解放出来,更有望通过构建系统化的知识库,为数据驱动的材料科学研究提供强大助力,加速新材料的创新周期。