从“看见”到“度量”:AI辅助定量一切
2025-08-28 · 5 min read
在生物医学和材料科学的研究中,显微图像是揭示微观世界奥秘的窗口。然而,仅仅“看见”是不够的,精确的“度量”——比如计算细胞大小、纤维直径或颗粒分布——才是推动科学发展的关键。这一切量化分析的前提,都依赖于一个看似简单却至关重要的元素:图像比例尺(Scale Bar)。
项目背景:量化分析中“失落的一环”
传统的量化分析流程中,研究人员需要手动在ImageJ等软件中标定比例尺,这个过程不仅繁琐、耗时,而且极易引入主观误差。更棘手的是,不同期刊、不同设备生成的显微图像,其比例尺样式千差万别,从简单的线段到复杂的标尺,给自动化处理带来了巨大挑战。
近年来,像SAM (Segment Anything Model) 这样的视觉大模型展现了强大的“分割一切”的能力,但它们解决了“是什么”的问题,却无法回答“有多大”的问题。如果不能自动获取图像的物理尺度,这些先进的分割模型在量化分析上就英雄无用武之地。本项目旨在打通这“最后一公里”,开发一个能自动、精准提取各类比例尺信息的AI系统,并与分割模型结合,实现真正的“万物可测”。
技术方案:端到端识别与交互式测量的智能系统
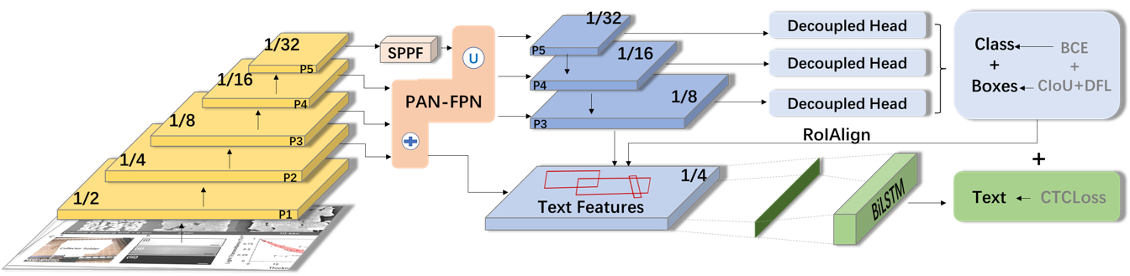
本项目的核心是一个端到端的智能系统,它由两部分组成:一个用于自动提取比例尺信息的 YOLO-OCR模型,以及一个集成了该信息、并由 MicroSAM 驱动的交互式测量前端。
1. 数据驱动:构建全球首个大规模比例尺标注数据集
由于缺乏公开可用的数据集,项目首先构建了一个包含 14,000张真实科学图像和 5,726张合成图像的大规模比例尺数据集(SciScale-DB)。数据集覆盖了矩形、I形、箭头形等八大类常见的比例尺样式。通过合成数据进行预训练,再利用真实数据进行主动学习和微调,极大地降低了标注成本,并提升了模型的泛化能力。
2. 核心模型YOLO-OCR:实现目标检测与文字识别的统一
与“先检测框、后识别文字”的两阶段方法不同,本项目采用了一个经过改进的端到端YOLO-OCR模型。该模型基于先进的YOLOv11架构,在一个统一的网络中同时完成三项任务:
- 比例尺(Scale Bar)检测
- 比例尺标签(Scale Label)检测
- 比例尺标签文字识别
这种端到端的设计,使得模型可以利用比例尺和其标签通常共同出现的上下文信息,从而提升整体的识别精度和效率。
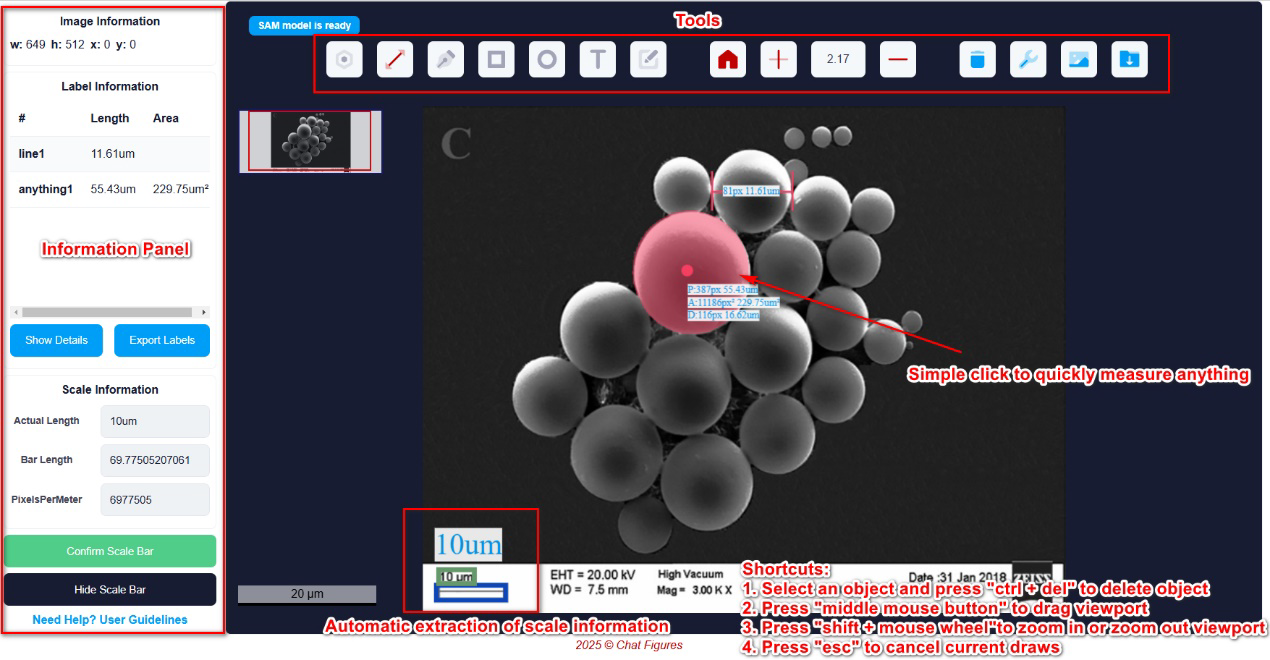
3. 系统集成:与SAM结合,赋能“万物可测”
提取出的比例尺信息(例如,100像素对应10微米)被无缝集成到一个交互式测量系统中。该系统的前端利用了MicroSAM——一个在海量显微图像上微调过的SAM模型。用户只需在图像上简单点击或框选感兴趣的区域,系统就能:
- 自动分割出目标对象。
- 即时计算出目标的真实物理尺寸(如直径、面积等)。
成果与验证
1. 高精度的识别性能
在包含1400张图像的测试集上,YOLO-OCR模型展现了卓越的性能:
- 比例尺和标签的检测精度(Precision)达到了98.0%。
- 比例尺标签的文字识别精度达到了96.6%。
该性能显著优于传统的两阶段方法,证明了端到端统一模型的优越性。
2. 与通用视觉大模型的对比
为了验证专用模型在特定任务上的优势,项目还将本系统的量化分析能力与多个顶尖的通用多模态大模型(如ChatGPT-4o, Gemini 1.5 Pro)进行了对比。任务是估算图像中特定物体的物理尺寸。
3. 可交互的在线应用
项目的最终成果是一个公开可用的在线Web应用(AI-Fiber)。它提供了一个直观的界面,用户可以上传本地图像,或通过浏览器插件直接分析网页上的显微图像,真正实现了“即看即测”,极大地降低了科研人员进行量化分析的技术门槛。
在线体验该项目https://chatfigures.com/